《表1 训练完成后的不同模型在战略性游戏上的测试得分》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
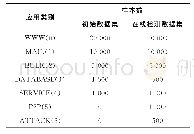
测试得分结果如表1所示,根据平均得分和最高得分的数据,均可以看出:与其余三种算法相比,训练完成后的LDF-IPER-DDQN在指导Agent进行这8种游戏时的得分都高于其它三种算法.特别地,在SpaceInvaders和Berzerk这两个游戏中性能提升地非常明显.这充分证实了我们的猜想,LDF-IP-ER-DDQN不仅仅能够在训练过程中表现得很好,在训练完成完成后的测试阶段也优于其余算法模型.总而言之,与训练过程类似,针对这8种游戏,四种算法的性能基本保持了LDF-IPER-DDQN>LDF-PER-DDQN>DF-PER-DDQN>PER-DDQN的态势.5.3实验总结
| 图表编号 | XD00107162400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 陈松、章晓芳、章宗长、刘全、吴金金、闫岩 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室、苏州大学计算机科学与技术学院、吉林大学符号计算与知识工程教育部重点实验室、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}