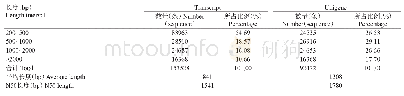
《表1 番红花转录组测序数据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在NCBI序列片段存档数据库(Sequence Read Archive,SRA)中选取番红花(Crocus sativus L.)开花期(开花前、开花时、开花后)转录组数据(SRP056059)(Baba等2015),在高通量基因表达数据库(Gene Expression Omnibus,GEO)中选取番红花球茎、萼片、叶、柱头和雄蕊组织转录组数据(SRP052616)(Jain等2016),相关信息见表1。7个番红花转录组数据组装前先进行数据过滤,即除去含接头、含N比例大于10%,以及低质量的原始读数序列(质量值Q≤20的碱基数占整个原始读数的40%以上),以获得高质量纯净读数(clean reads)数据。
| 图表编号 | XD00144021000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.20 |
| 作者 | 周琳、杨柳燕、蔡友铭、王桢、张永春 |
| 绘制单位 | 上海市农业科学院林木果树研究所上海市设施园艺技术重点实验室、上海市农业科学院林木果树研究所上海市设施园艺技术重点实验室、上海市农业科学院林木果树研究所上海市设施园艺技术重点实验室、上海市农业科学院林木果树研究所上海市设施园艺技术重点实验室、上海市农业科学院林木果树研究所上海市设施园艺技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}