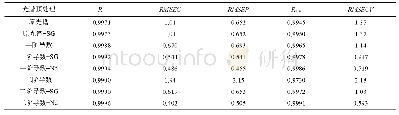
《表5 不同光谱预处理的掺入玉米、花生油的山茶油掺假样品建模结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
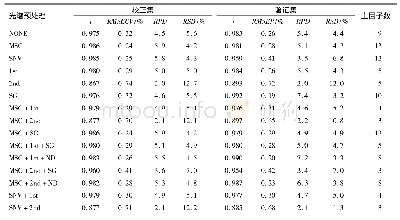
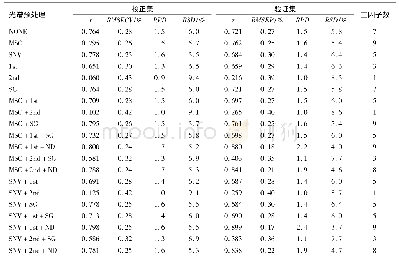
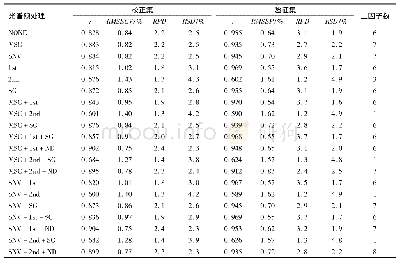
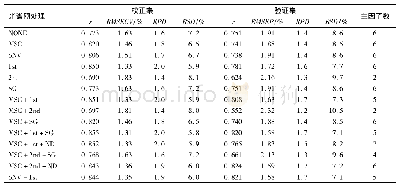
样品本身物理性质、环境因素、高频仪器自身噪音等因素会影响样品红外谱图的采集,引起基线漂移和光谱重现性较差等问题,因此需采用预处理方法消除噪声[19]。一阶导数和二阶导数可降低光谱峰的偏移和飘移,SG(Savitaky-Golay filter)和Nd(Norris-derivative filter)滤波可对光谱进行平滑处理。在选择最佳光谱波段的基础上,对样品进行不同的预处理,采用PLS方法分别建立多元掺假体系的山茶油掺假预测模型,所建模型的校正集、预测集和交叉验证集的结果见表3、表4和表5。由表可知,不同预处理方法建立的模型性能指数都达到0.99以上,均方差也在较低的范围内,预测效果均没有明显差别。但是细比之下,各模型还是有优劣之分。采用原光谱或者原光谱+SG平滑得到的模型预测效果相对比较差,单独采用一阶导数或者二阶导数处理,虽然可提高光谱分辨率,但模型预测能力也不佳,说明SG和Nd平滑处理可提高信噪比,减少随机噪音。另外,由表还发现,相同阶数情况下,Nd平滑方法优于SG平滑。通过预测模型的精度衡量标准,掺有玉米油、花生油的二元体系山茶油掺假模型最优预处理方法都是一阶导数+Nd,二阶导数处理的图谱使光谱差异更明显,但也放大了噪声信息,反而使预测能力下降,而掺有玉米油和花生油的三元体系山茶油掺假模型采用二阶导数+Nd的预处理方法,所建模型的预测能力较高。
| 图表编号 | XD00138419900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.25 |
| 作者 | 姚婉清、彭梦侠、陈梓云、张家蔓、林量谦、甘海昌 |
| 绘制单位 | 嘉应学院化学与环境学院、嘉应学院化学与环境学院、嘉应学院化学与环境学院、嘉应学院化学与环境学院、嘉应学院化学与环境学院、嘉应学院化学与环境学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}