《表6 在MSRA语料上的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
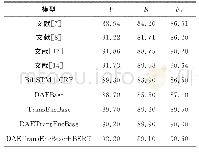
为了验证本文方法的泛化能力,我们选择与Zhou等的实验结果进行对比。表6给出了在MSRA语料上与其他模型的对比实验结果。文献[13]首次提出基于词的CRF模型和使用大量精心制作的特征,在MSRA语料上达到了86.51的F值。文献[14]的方法针对片段级中文命名实体识别进行研究,联合使用多种不同的特征模板,在MSRA语料上获得了较好的性能。这两种方法都基于传统的统计学习模型,依赖人工特征设计和专业知识。文献[15]为了减弱系统对人工特征设计的依赖,采用深度学习片段神经网络结构,实现特征的自动学习,在MSRA语料上对人名、地名和机构名识别的总体F值达到了90.27%。实验结果显示,与以上方法相比,本文提出的融合字词模型的命名实体识别方法获得较好的系统性能,在人名和地名识别结果上比最好的系统分别提升了1.04%、0.35%。
| 图表编号 | XD00109149000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 殷章志、李欣子、黄德根、李玖一 |
| 绘制单位 | 大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
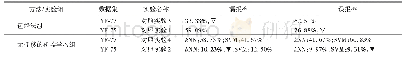



{kind=link}