《表3 在MSRA-TD500数据集实验对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
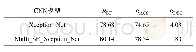
MSRA-TD500数据集是中英文混合的任意方向场景文字数据集,主要以中文为主。表3给出了在该数据集上的测试对比实验结果,如表3第3至第5列的结果所示,本文方法的F-score值为81.1%,仅比CRAFT低1.8个百分点,与其他最新方法相比,本文方法在检测性能上具有绝对优势,在该数据集上本文方法的速度高于绝大多数对比方法。图5(c)给出了本文方法在MSRA-TD500数据集上的一些主观测试结果实例,从图中可以看出,本文方法可以准确检测和识别场景中的混合文字。为了进一步验证本文方法对中文检测的优越性,图6中给出了本文方法和CRAFT[22]和EAST[8]两种方法对中文的检测对比结果。在图6中可以看到,EAST算法检测的文字框只包含了文字的一部分,不能准确地包含完整的文字实例,本文中的文字逼近方法可以有效地调整文本框使其一方面充分包含文字内容,另一方面又保证了文字框和文字实例的贴合度,在很大程度上改善了EAST算法的检测结果。CRAFT算法难以检测一些较大的或不连通的中文单字,从而导致存在字符漏检的问题,本文基于谱聚类的汉字分割可以有效解决这一问题,从而提高场景中汉字的检测率。无论是图5(c)和图6的主观结果还是从表3中的客观数据均表明本文的方法对场景图像中的汉字有很好的检测定位效果,对中文检测的性能明显高于CRAFT和EAST算法。
| 图表编号 | XD00201621400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.15 |
| 作者 | 赵凡、张琳、闻治泉、杨林林、蔺广逢 |
| 绘制单位 | 西安理工大学印刷包装与数字媒体学院信息科学系、西安理工大学印刷包装与数字媒体学院信息科学系、西安理工大学印刷包装与数字媒体学院信息科学系、西安理工大学印刷包装与数字媒体学院信息科学系、西安理工大学印刷包装与数字媒体学院信息科学系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}