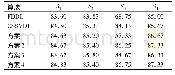
《表1 不同算法在LFW500与LFW500+noise数据集的测试结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先使用中心损失模型提取人脸特征,并在LFW500和LFW500+noise数据集上比较K-means算法,实验结果如表1的第2、3行所示:当没有噪声时,数据集的ID数量已知,F1度量得分0.93,K-means算法可以起到不错的效果;当噪声加入后,将噪声看作一类(k=501),F1度量得分0.81,K-means算法效果下降明显,这是噪声数据在特征空间的分布情况未知,不能准确估计噪声的类别数造成的。然后使用改进k近邻算法划分子空间,实验结果如表1的第5行所示,在每个子空间内按照“简单正样本、难正样本、噪声”的分类标准令k=3,F1度量得分0.91,说明子空间K-means可以更有效地处理噪声数据。最后对比基于中心损失模型的人脸特征与基于softmax模型的人脸特征在子空间K-means算法上的效果,实验结果如表1的4、5行所示,基于中心损失模型的人脸特征表现出更强的鲁棒性。
| 图表编号 | XD00104410500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.05 |
| 作者 | 王锟朋、钟汇才 |
| 绘制单位 | 中国科学院微电子研究所、中国科学院大学、中国科学院微电子研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}