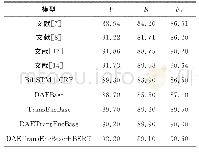
《表2 各模型在MSRA数据集上的F1值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
单位:%
为了验证本文所构建的模型性能,将其与现有的模型[7,8,12,14]进行了实验对比,结果如表2所示。文献[7]在基于词的序列标注任务上,通过添加手工标注来辅助学习句子的特征;文献[8]以字符为基础,利用条件随机场和最大熵模型来共同识别中文文本中的实体;文献[12]将中文NER构造为一个联合任务,同时执行边界识别和实体分类两个子任务;文献[14]采用对抗迁移学习的方法,将任务共享的词边界信息整合到中文NER任务中以缓解数据量不足的问题,并使用自注意力机制来捕获句子的全局依赖关系。虽然这几种模型都在一定程度上提高了实体识别的F1值,但是对文本序列中所蕴含的语义信息学习得还不够充分,导致模型有一定的局限性。本文构建的DAETransEncBase模型融合了Transformer Encoder和DAE的优点,可以帮助模型更充分地捕获上下文信息,提高实体识别的性能。加入预训练的BERT词向量后,不同语境中的语义信息得到更充分地表示,模型的泛化能力也进一步得到提升。与现有方法相比,虽然本文模型还没有达到最优,但足以证明本文所提方法的有效性。
| 图表编号 | XD00218594200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 张欣欣、刘小明、刘研 |
| 绘制单位 | 中原工学院计算机学院、中原工学院计算机学院、中原工学院计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}