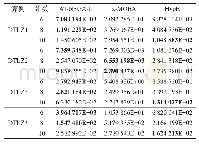
《表3 各算法在不同数据集上的F1-value对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验均在Jupyter Notebook上运行,其中在HSBC算法中,m1取10,m2取0.2时算法总体来看效果最好,因此本次实验取该值。对于每个数据集,按7:3的比例划分为训练集与测试集,5个数据集分别经过不做均衡化处理、随机欠采样(RUS)、随机过采样(ROS)、SMOTE算法、ADASYN算法及HSBC算法后使用GBDT算法对新训练集进行分类。F1-value及AUC对比结果见表3和表4,其中最大值用粗体标出。
| 图表编号 | XD00164190900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 史明华、吴广潮 |
| 绘制单位 | 华南理工大学数学学院、华南理工大学数学学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}