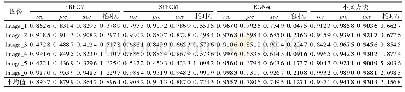
《表8 在MSR语料上的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
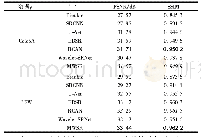
从上述例子中可以看出切分结果出现多词粘连的情况。这种切分错误在文献[22]中有谈到,该文献通过实验验证了基于字的分词方法往往忽略词所包含的组合信息,指出应用字词联合解码进行分词效果更佳。通过分析本文切分错误结果,同样验证了上述结论,而本文方法恰好缺少词信息进行分词指导学习,因此出现多词粘连的情况,影响了最终的分词性能。对比文献[21]的分词方法,通过门控组合神经网络对输入的字符序列进行候选词分布式表示,很好地引入了词信息,并用LSTM神经网络对所有切分结果进行打分,取打分最高的切分组合作为最终的分词结果,则最终的分词效果优于本文实验结果。在今后的实验中,本文将借鉴文献[21]的分词方法,引入词信息进行指导学习。
| 图表编号 | XD00134596500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 李对红、王裴岩、张桂平、张少阳 |
| 绘制单位 | 沈阳航空航天大学人机智能研究中心、沈阳航空航天大学人机智能研究中心、沈阳航空航天大学人机智能研究中心、沈阳航空航天大学人机智能研究中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}