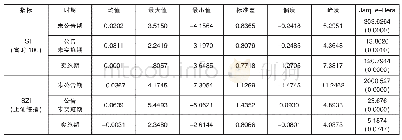
《表1 数据说明与指数收益率的描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
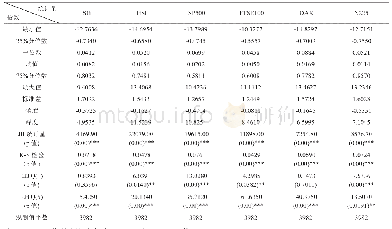
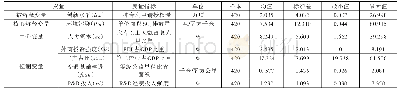
由于部分成份股是新近加入指数编制,而部分成份股的上市时间较短,我们剔除了数据存在缺失的成份股,而最终保留数据完整的成份股来跟踪指数。同时出于交易成本的考虑,购买指数中的所有成份股是不合算的,通常需要在进行优化配置之前选择部分成份股进入跟踪组合。借鉴Ling等[36]的思想,我们基于指数和成份股的收益率数据,依次计算出所有成份股的Beta值。由于增强指数模型的首要任务是跟踪指数的趋势,所以选择Beta值最接近1的成份股构建跟踪组合的股票池。此外,Ling等[36]的研究中,还考虑了随机Beta和最大Beta标准选择成份股,这两个标准与跟踪指数趋势的内涵相差较远,不是本文考虑的内容。根据五个指数所含成份股的数量,最终选取的进入跟踪组合的成份股数量分别是10、25、30、50和100。表1给出了样本数据说明和指数收益率的描述性统计。第2列给出各指数包含的成份股数量,第3列给出进入跟踪组合的成份股数量,第4列是样本量。第5-10列给出了各指数收益率的描述性统计,均值显示五个将上述五个数据集的估计样本代入模型EIM,并设定相应的具体约束条件,求解模型可以得到最优的投资策略。由于指数编制中成份股的份额不可能为负,所以我们在约束条件中设定li=0,ui=1,i=1,2,…,n。为了比较不同τ对投资策略表现的影响,我们取六个不同参数值,即τ=0,1,2,3,4,5。为比较最优投资策略在实际中的表现,我们引入三个常用的投资绩效评价指标:夏普比率(Sharpe Ratio,SR)、信息比率(Information Ratio,IR)和欧米茄比率(Omega Ratio,OR)。计算公式如下:
| 图表编号 | XD0098159800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 黄金波、吴莉莉、尤亦玲 |
| 绘制单位 | 广东财经大学金融学院、珠三角科技金融产业协同创新发展中心、广东财经大学金融学院、广东财经大学金融学院 |
| 更多格式 | 高清、无水印(增值服务) |

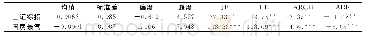

{kind=link}