《表2 数据集组成:基于CNN-LSTM的歌曲音频情感分类》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
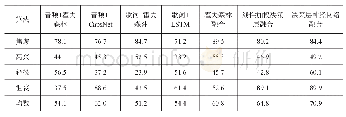
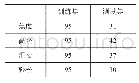
本文用于实验的数据集来自Million Song Dataset(百万歌曲数据集)中的Last.fm标签子集[15],从中抽取4种情感标签歌曲列表,情感标签分别为愤怒(angry)、高兴(happy)、放松(relaxed)和悲伤(sad)。通过python编写脚本工具,从各大音乐网站爬取标签列表下的歌曲音频文件,并进行人工筛选。对歌曲文件进行预处理,去掉多为背景音的前5 s数据,拆分为30 s的歌曲片段,用来统一不定长的音频数据。设定采样频率为8 kHz、单声道,每个30 s音频片段提取到的实际帧数为469帧,并通过随机划分的方式,将歌曲片段样本集划分为80%训练集和20%测试集。数据集组成如表2所示。
| 图表编号 | XD0077400000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.10 |
| 作者 | 陈长风 |
| 绘制单位 | 杭州电子科技大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}