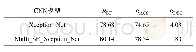
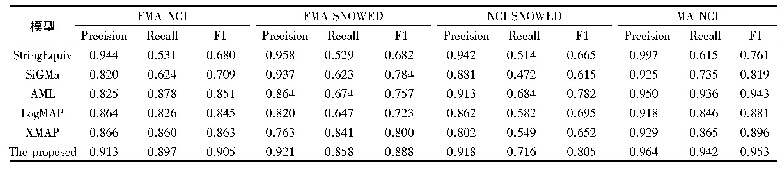
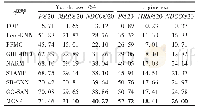
《表3 模型在子数据集上的能力对比》
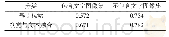 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了进一步分析模型方法的效果,在Con-text数据集中,分别划分了包含文字与不包含文字的2个子数据集。同时在2个数据集上分别训练2个模型。模型给出基于视觉方法与视觉与文本融合2种方法的结果,表3为所有分类最终的m AP值。从中可以看出视觉与文本信息融合的方法相比只基于视觉方法对图像分类有很大的提升,并且图像中文字越多越有效果。此外还注意到在不含文字的图像集上性能略微有所提升,可能是因为使用共享参数的多监督网络,其方法最终分类结果是由视觉特征fv,文本特征fa以及文本与视觉融合特征共同决定,而文本特征fa在文本识别特征提取部分与相关度计算时都要用到视觉特征信息fv,故可能在训练过程中文本识别对视觉识别相关参数有一定的促进作用,最后方法整体上有所提升。
| 图表编号 | XD0059465800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 袁建平、陈晓龙、陈显龙、何恩杰、张加其、高宇豆 |
| 绘制单位 | 北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、华北电力大学控制与计算机工程学院、华北电力大学控制与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}