《表4 统计特征差异:一种基于迭代的关系模型到本体模型的模式匹配方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
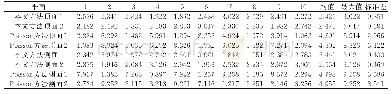
数据库和本体中相同含义数据的统计特征也存在一定的差异,在实验中,基于餐行健系统生成的本体模型中多为高端餐饮企业,而品智餐饮系统中则是中小餐馆居多,因此两个系统中表述相同含义的元素的统计特征(最大值、平均值、标准差等)存在较大差异(见表4).在匹配过程中,商户账单支付表在两个系统中模式结构相似度较高,得到了匹配,利用这个信息可以得到很多匹配的元素对,利用已匹配的元素对的统计特征生成样本并训练分类器.随着分类器的训练样本增加,分类器更容易识别出数据库和本体中的统计特征差异,可以把具有类似差异的相同概念进行匹配.在本例中,商户账单明细表数据库和本体的匹配通过这种方式得到了提升.也体现ISOMA基于迭代更好地兼容了数据源的本地化特征.
| 图表编号 | XD0056217000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 王丰、王亚沙、赵俊峰、崔达 |
| 绘制单位 | 高可信软件技术教育部重点实验室(北京大学)、北京大学信息科学技术学院、高可信软件技术教育部重点实验室(北京大学)、软件工程国家工程中心(北京大学)、北京大学(天津滨海)新一代信息技术研究院、高可信软件技术教育部重点实验室(北京大学)、北京大学信息科学技术学院、北京大学(天津滨海)新一代信息技术研究院、高可信软件技术教育部重点实验室(北京大学)、北京大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}