《表2 长文本分类算法的实验结果 (准确率) 对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
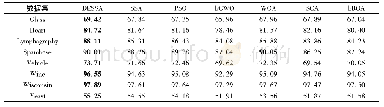
本文是对话题归类进行的多分类实验,在评价模型性能时使用宏平均准确度。表2是长文本部分的实验结果,分析此结果可知:实验过程中为了提升文本分类效果,应保留文档的出处。无出处时Data1基于TextCNN测试的准确率是78.73%,有出处时准确率是80.91%。由Bi-LSTM和Bi-GRU的执行情况可以看出,Bi-GRU在长文本分类中效果优于CNN、TextCNN和Bi-LSTM。所以TSO-HHAN模型中采用Bi-GRU进行字、词、句的序列编码。另外,各算法的准确率与数据集的分布情况和数据量也相关。Data2的数据分布比较均匀,而且数据量大,所以各算法对应的准确率都最高,HAN-WC的结果略低于Bi-GRU,差0.01%。中文数据Data1和Data2对应的HAN-WC都优于HAN-W和HAN-C,说明HAN-WC不仅挖掘了形态学上汉字的原始含义,还挖掘了中文词语的语义特征,这种字词向量混合表示方法对中文分类算法有一定的提升。同时也说明,对于中文文本来说,基于字词—句的层次注意力网络优于基于词语—句和字—句的层次注意力网络。从英文数据Data3和Data4的运行结果来看,基于注意力的分层网络优于其他深度学习算法。4个数据集的HAN模型的准确率比其他神经网络模型的最高准确率依次提升了5%、0%、2%、5%。综上所述,本研究中长文本分类算法采用HAN-WC是有效的,并具有一定的泛化能力。本研究中英文文本的最小粒度为单词,所以HAN-WC的结果取自HAN-W的结果。
| 图表编号 | XD0054907000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 车蕾、杨小平、王良、梁天新、韩镇远 |
| 绘制单位 | 中国人民大学信息学院、北京科技大学信息管理学院、中国人民大学信息学院、中国人民大学信息学院、中国人民大学信息学院、中国人民大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |
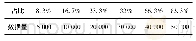


{kind=link}