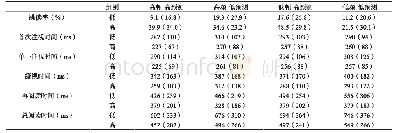
《表2 实验一各实验条件下目标词跳读概率和凝视时间的均值和标准差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《阅读中词汇识别依赖词内字序编码的阶段性特点:眼动证据》
被试对于问题回答的正确率都在85%以上,且呈现条件主效应不显著(p>0.05),表明被试均认真阅读各种呈现条件下的句子。注视点的持续时间过长或是过短都被认为不能反映正常的词汇加工,根据以往研究的做法将小于80ms或大于800ms的注视点数据剔除(Angele,Slattery,Yang,Kliegl,&Rayner,2008;Yang,Wang,Xu,&Rayner,2009),总计剔除数据小于4.5%。根据本研究的目的,报告基于目标词汇兴趣区域的跳读概率和凝视时间两项指标。跳读概率是指第一遍阅读中被跳读的目标词数与其总目标词数之间的比率;凝视时间则是第一遍阅读中在目标词汇兴趣区内所有注视点持续时间之和(离开目标词汇兴趣区后再次进入兴趣区的注视点不在考虑范围内)。词汇的跳读概率反映预视阶段内的词汇加工(Reichle,Rayner,&Pollatsek,2003),因而不能作为衡量整体词汇加工过程的决定性参考。由于预视效应普遍存在(Rayner,1998),因而凝视时间同时反映预视和注视阶段内的词汇加工,因而该指标能够较为完整地反映词汇加工过程。采用lme4包构建线性混合模型在R中分析上述指标,其中凝视时间作为连续变量处理,跳读概率被作为两分变量处理(Baayen,Davidson,&Bates,2008;Bates,M?chler,&Bolker,2011;Barr,Levy,Scheepers,&Tily,2013)。鉴于跳读概率本身还会损失部分信息,故从反映词汇加工的完整性和敏感性方面考虑,本研究主要基于“凝视时间”指标结果做出推论,将“跳读概率”作为辅助性指标说明研究问题。表2列出了实验一各条件下基于被试的跳读概率和凝视时间均值和标准差。
| 图表编号 | XD0053420500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.20 |
| 作者 | 刘志方、陈朝阳、仝文、苏衡 |
| 绘制单位 | 杭州师范大学心理学系、宁波大学心理学系、山西师范大学心理学系、浙江大学心理与行为科学系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}