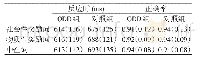
《表3 实验一各组被试在高频和低频目标词汇条件下基于目标词汇眼跳数据的均值与标准差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
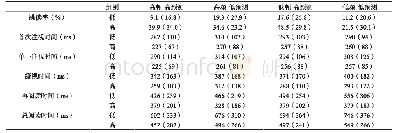
注:眼跳幅度的单位是弧度,概率单位是%。
实验中所有被试回答判断问题的正确率均为85%以上,说明被试在实验过程中认真阅读了实验句子。剔除练习句和判断句的数据后,还删除了三个标准差之外数据,共删除1.79%的数据。本研究基于线性混合模型分析因变量数据,这种模型可排除被试和项目的随机效应,以及固定效应在被试和项目上的随机斜率差异),从而更加准确地考察实验操作产生的固定效应(Barr,Levy,Scheepers,&Tily,2013;Bates,Maechler,Bolker,&Walker,2015)。本研究的具体作法是在R环境中使用lme4统计软件包。分析数据时的模型选用步骤如下:首先,运行包含被试、项目随机效应以及所有固定效应在被试和项目上的随机斜率的全模型;然后,在这个模型的基础上逐步简化模型;最后,通过对比能够收敛的所有模型的拟合度,选择最优模型:当较复杂模型的拟合度优于较简单模型时选择较复杂模型,当较复杂模型的拟合度与较简单模型没有差异时,选择较简单模型。鉴于在R中构建模型分析各项数据的对数的结果趋势与分析原始数据的结果趋势完全一致,结果仅报告基于原始数据分析的回归系数b、标准误SE以及t值(t=b/SE),以及p值。各项眼动指标的平均值见表2和表3。
| 图表编号 | XD00112862100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.15 |
| 作者 | 刘志方、仝文、张骏 |
| 绘制单位 | 杭州师范大学教育学院、山西师范大学心理学系、山西师范大学心理学系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}