《表2 测试数据集统计表:基于注意力模型的多传感器人类活动识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
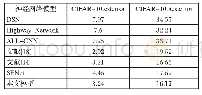
UCI_HAR数据集不属于自然型数据,直接将其标签复制为像素级标签的做法会导致训练集中没有可“分割”的数据,既不符合分割任务的要求也不利于模型收敛。因此,在分割实验中只考虑Skoda数据集和Oppor数据集;这2个数据集均属于类不平衡数据集,如果窗长太小,则大量训练样本不可分割;如果窗长过大,虽然可以保证每个数据对应标签的丰富程度,但会极大的减少样本数量。为保证绝大多数训练数据的标签至少包含2个不同的类别,针对2种数据集的窗长与覆盖率重新调整,将分割好的Skoda数据集数据按照4∶1的比例分割为训练集和测试集。将Oppor数据集按照前3位志愿者为训练集,第4位志愿者为测试集的方式分割。将所有数据沿时间方向进行归一化后,最终调整结果如表2所示。
| 图表编号 | XD003593700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.22 |
| 作者 | 王金甲、周雅倩、郝智 |
| 绘制单位 | 燕山大学信息科学与工程学院、燕山大学河北省信息传输与信号处理重点实验室、燕山大学信息科学与工程学院、燕山大学河北省信息传输与信号处理重点实验室、燕山大学信息科学与工程学院、燕山大学河北省信息传输与信号处理重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}