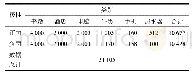
《表1 实验数据统计:用于目标情感分类的多跳注意力深度模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
目前,用于情感分析的中文标注语料并不丰富,且大多存在样本数量不足、涵盖领域有限等问题。本文提出的模型主要用于解决针对领域的中文文本情感计算,因此为了能够有效完成模型的训练和测试,本文采用一个包含6类领域数据的公开中文数据集进行实验。该语料文本涉及的6个领域分别是书籍、酒店、电脑、牛奶、手机和热水器,每类领域数据均由用户评论组成,数据样本按照情感极性分为正面和负面两大类。实验数据统计如表1所示。最后,每类领域数据按照情感极性,被随机分成数量相同的两部分,一半作为训练数据对模型进行训练,另一半作为测试数据用于模型性能评测。
| 图表编号 | XD00100523400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.30 |
| 作者 | 邓钰、雷航、李晓瑜、林奕欧 |
| 绘制单位 | 电子科技大学信息与软件工程学院、电子科技大学信息与软件工程学院、电子科技大学信息与软件工程学院、电子科技大学信息与软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}