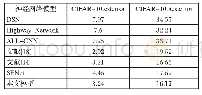
《表2 在Penn Action数据集下使用与未使用自注意力识别精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
unit:%
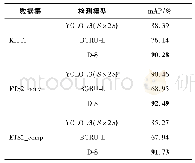
综上所述,并不是所有的帧都对行为识别有益,与类别无关的行为会扰乱行为识别的最终结果。通过使用自注意力机制,网络会自动给每一帧分配相应的权重,越有利的帧其权重越高,学习到的时序特征也会更有效,最终改善了行为识别的精度。在Penn Action和JHMDB数据集上,对使用自注意力机制前后的RGB特征、骨骼特征以及融合特征进行了对比实验。从表2和表3可以看出,使用自注意力后相较于未使用自注意力时的识别精度提升了1.5%左右。在使用自注意力机制后,仅使用RGB特征、仅使用骨骼特征以及使用两者融合特征的识别效果都有了明显的提升,由此说明网络能够更有效地提取视频序列的时序特征。
| 图表编号 | XD00188334900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 郭伏正、孔军、蒋敏 |
| 绘制单位 | 江南大学模式识别与计算智能国际联合实验室、江南大学模式识别与计算智能国际联合实验室、江南大学模式识别与计算智能国际联合实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}