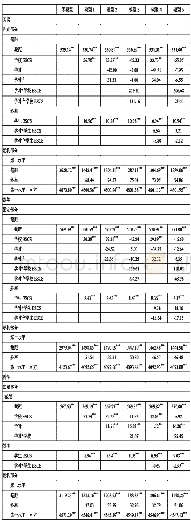
《表7 Flickr30k-cn上标签增强对于Google模型的影响》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表6、表7中分别展示了在两个中文数据集Flickr8k-cn和Flickr30k-cn上,两种方法,即重排序候选词语与重排序候选句子的效果以及与基线方法结果的对比.其中基线方法记为Google模型.与未重排的Google模型相比,不论是使用MLP模型的预测标签,还是使用答案标签,重排序候选词语的方法均没有带来改善.而重排序候选句子方法,在使用答案标签进行重排时,在两个数据集上、每个指标上都有了很大的提升.比如CIDEr指标在Flickr8k-cn上由基线方法的47.4提升到59.5,在Flickr30k-cn上由基线方法的32.5提升到42.1.这表明,当标签信息质量很高时,句重排方法可以有效地提高预测句子的质量.同时,如表格所示,使用本文提出的MLP模型预测标签的句重排方法,与基线方法对比,每个指标都有更高的得分,也有效地提升了预测句子的质量,是所有不使用答案的方法中效果最好的方法.
| 图表编号 | XD0035538200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 李锡荣 |
| 绘制单位 | 中国人民大学数据工程与知识工程教育部重点实验室、中国人民大学信息学院多媒体计算实验室 |
| 更多格式 | 高清、无水印(增值服务) |




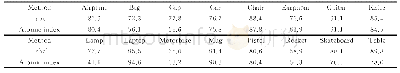
{kind=link}