《表7 几种不同模型在Flickr30k数据集上的面向具体任务的性能比对》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
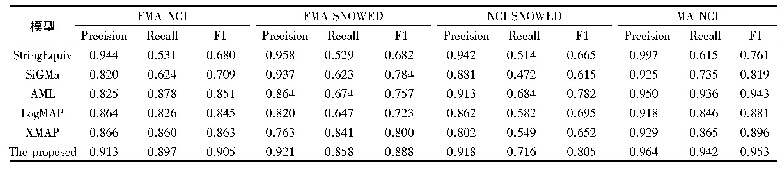
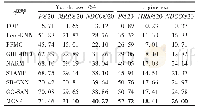
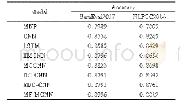
面向具体任务的评估是直接在具体的任务上进行训练,本质上属于有监督的训练,见表5,面向具体任务的训练效果明显好于零样本学习评估的效果.视觉语言表征模型可以针对MSCOCO和Flickr数据集的句子检索和图像检索任务进行有监督训练,从而评估模型好坏.另外一些有监督的任务包括多标签分类等.NUS-WIDE是一个多标签分类的数据集[88],黄等人将基于社交网络图片学习的视觉与文本联合表征,可以在NUS-WIDE数据集上进行评估[89].一般基于相似性的表征学习架构会采用这种评估方式,同样采用Flickr30k数据集.表7中列出了一些模型直接基于跨模态检索任务进行训练得到的性能评估.
| 图表编号 | XD00207323000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 杜鹏飞、李小勇、高雅丽 |
| 绘制单位 | 可信分布式计算与服务教育部重点实验室(北京邮电大学)、北京邮电大学网络空间安全学院、可信分布式计算与服务教育部重点实验室(北京邮电大学)、北京邮电大学网络空间安全学院、可信分布式计算与服务教育部重点实验室(北京邮电大学)、北京邮电大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}