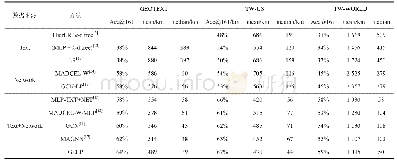
《表3 几种过采样方式在Twitter image dataset数据集上的性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
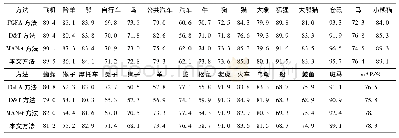
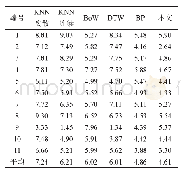
为了验证模型在普通图像的情感分类任务是否遵循这一原则,我们在公开数据集Twitter image dataset上进行了实验.该数据集由普通图片构成,由亚马逊人工标注平台经5人标注,有3-agree,4-agree,以及5-agree 3个数据集,分别包含1269,1115,以及882张图片.在图片标记过程中,对于1张待标记的图片,若5人中有3人给出的标签一致,则此图片被收集到3-agree中,若5人中有4人给出的标签一致,则此图片被收集到3-agree,4-agree中,若5人的标记结果一致,那么这张图片将被同时收集到3-agree,4-agree,以及5-agree中,其他情况下的图片直接舍弃.为了保证数据标签的准确性,我们仅在5-agree数据集上进行了实验,以裁剪+翻转过采样的方式作为baseline,在此基础上分别对原图像亮度、色相、饱和度,以及对比度随机增加或者减少0~50%,实验结果见表3.
| 图表编号 | XD0039019200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.20 |
| 作者 | 张浩、徐丹 |
| 绘制单位 | 云南大学信息学院、云南大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}