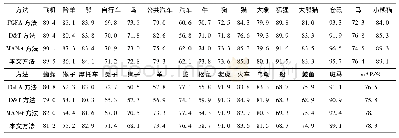
《表7 在Image Net VID数据集上的测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于时空卷积特征记忆模型的坦克火控系统视频目标检测方法》
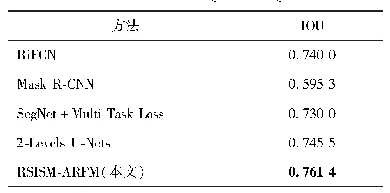
除了在本文构建的TKHK VID数据集上进行实验外,还在通用数据集Image Net VID上对本文方法进行测试。Image Net VID数据集有30类目标,共5 354段视频,其中训练集、验证集以及测试集中所包含的视频段数量分别为3 862、555和937.采用的对比方法为FGFA、D&T以及MANet3种方法。由于Image Net VID数据集中的数据多于TKHK VID数据集,本文方法在训练过程中使用4个RTX 2080Ti GPU进行120 000次迭代训练,其中前80 000次和后40 000次迭代训练的学习率分别是0.001和0.0 001,其余参数保持不变。表7展示了4种方法在TKHK VID数据集上的测试结果。从表7中可以看出,本文方法取得的m AP达到78.3%,优于FGFA以及D&T方法,与MANet方法基本持平。从各方法取得的单个目标类型AP来看,本文方法取得部分目标类型的较高,如熊、汽车等,但也存在部分目标类型的AP较低,如老虎、斑马等,但整体的检测效果最佳。相对于TKHK VID数据集,Image Net VID数据集中的目标尺寸较大,因此与表1相比,表7中各方法取得的m AP较高。
| 图表编号 | XD00182612500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 戴文君、常天庆、褚凯轩、张雷、郭理彬 |
| 绘制单位 | 陆军装甲兵学院兵器与控制系、陆军装甲兵学院兵器与控制系、陆军装甲兵学院兵器与控制系、陆军装甲兵学院兵器与控制系、陆军装甲兵学院兵器与控制系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}