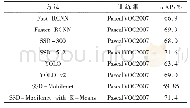
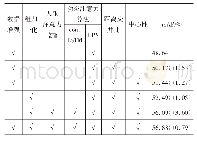
《表2 不同结构网络模型在Image Net VID数据集上对应的各类别AP和m AP值比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
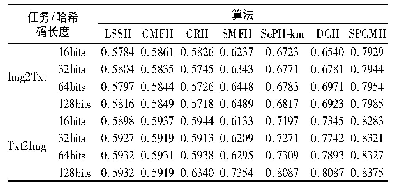
注:加粗字体为每行最优结果。
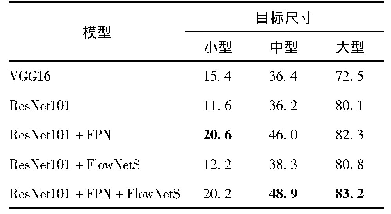
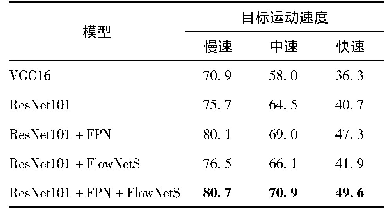
在本文模型中,ResNet101利用残差结构加深网络模型,使用深层网络模型描述数据。而特征金字塔网络和光流网络分别通过空间特征融合和时间特征融合来增强特征。为了验证这3个模块对检测性能的影响,在SSD目标检测框架下,在ImageNet VID数据集上分别对基于VGG16、ResNet101、ResNet101与特征金字塔(ResNet101+FPN)、ResNet101与光流网络(ResNet101+FlowNetS)以及ResNet101与时空融合(ResNet101+FPN+FlowNetS)等5种结构的网络模型进行实验,实验结果如表2所示,表2列出了5种不同结构的网络模型在ImageNet VID验证集上对应的各类别的AP以及m AP值。可以看出,VGG16模型的m AP明显小于ResNet101模型的m AP,表明深层网络模型的使用可以提高检测准确率。与ResNet101模型相比,ResNet101+FPN、ResNet101+FlowNetS、ResNet101+FPN+FlowNetS模型的m AP从65.0%分别提升到70.8%、65.9%和72.0%,表明时空特征融合通过结合近邻帧的特征以及多尺度的特征能够增强当前帧的特征,提升检测准确率。
| 图表编号 | XD00216442800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.16 |
| 作者 | 尉婉青、禹晶、柏鳗晏、肖创柏 |
| 绘制单位 | 北京工业大学信息学部、北京工业大学信息学部、北京工业大学信息学部、北京工业大学信息学部 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}