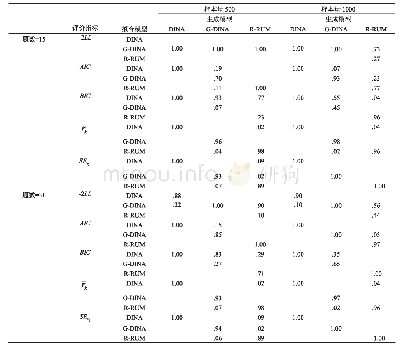
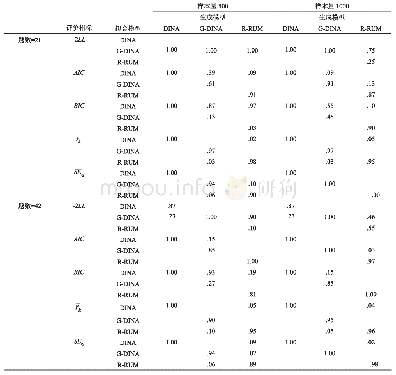
《表1 测验水平的模型-数据拟合指标》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先,表1呈现了HO-PINC和Fuzzy-DINA针对5个实证数据的测验水平模型-数据拟合指标值。根据ppp值可知,除data.pisa00R.ct外,两模型均较好地拟合其余4个实证数据。对data.pisa00R.ct而言,ppp值接近不拟合的边缘,尤其是Fuzzy-DINA。其次,根据DIC和–2LCPO两个相对拟合指标值,表明Fuzzy-DINA对5个实证数据的拟合均稍优于HO-PINC。另外,两模型的题目水平PPMC(篇幅限制未呈现)在各题目上的值较为一致,表明两模型对各题目的绝对拟合情况较为相似,没有出现某模型单独适用于某题目的情况。再有,图1呈现了两模型的题目参数估计值(篇幅限制仅呈现前两个数据的)。可发现,两模型的题目参数估计结果基本一致。经过计算,两模型的题目参数估计值之间的平均差异均小于.005。表2汇总了两模型的属性估计值。首先,为呈现概率属性(δ)和模糊属性(t)估计值之间的差异,本研究对每个属性计算了两者之间的平均绝对差异该值越大表明两者之间差异越大。其次,为了呈现δ和t估计值之间的相似性,本研究对每个属性计算了两者之间的皮尔逊相关。表2中结果表明δ和t估计值之间的差异较小,具有较高的相似性。另外,本研究还计算了两模型的高阶潜在能力估计值之间的相关性。5个数据中的相关系数依次为.999、.999、.998、.999和.999。结果表明两模型估计的是同一高阶潜在能力。综上所述,实证研究数据分析表明,尽管(a)相比于HO-PINC,Fuzzy-DINA对5个实证数据的相对拟合稍好,但(b)HO-PINC与Fuzzy-DINA的模型参数估计值之间的差异较小,具有较高的一致性。
| 图表编号 | XD00227225700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.20 |
| 作者 | 詹沛达、田亚淑、于照辉、李菲茗、王立君 |
| 绘制单位 | 浙江师范大学教师教育学院、浙江师范大学教师教育学院、浙江师范大学教师教育学院、浙江师范大学教师教育学院、浙江师范大学教师教育学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}