《表1 函数奖励值设置:基于区域扩张策略的势场强化学习算法路径规划研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
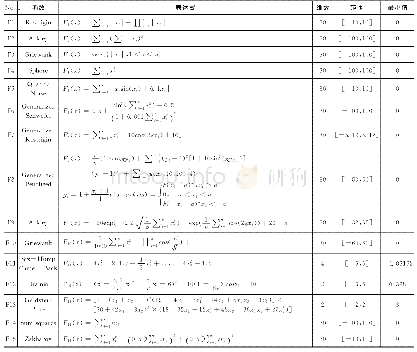
综合考虑机器人行驶每一步决策动作而不是寻找到目标点才得到奖励值,在对奖励值设计时,设定为每一步动作都会获得对应奖励值,根据每一步的动作情况不同设计不同的回报函数值。表1是根据探索动作出现的情况设计的回报函数。靠近目标点获得正奖励值、远离目标获得负奖励值、如果与障碍物发生碰撞获得较大的负奖励值。为了避免机器人与障碍物或其他机器人相撞、对机器人每一个单元格的移动设计最小安全距离。只要机器人与障碍物或其他机器人距离大于最小安全距离dq,则认为两车不会相撞。
| 图表编号 | XD00211782900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 阳杰、张凯 |
| 绘制单位 | 西安工程大学电子信息学院、西安工程大学电子信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}