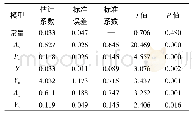
《表2 DDPG网络结构:基于模仿学习和强化学习的智能车辆换道行为决策》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
细化决策模块各DDPG子模块网络结构如表2所示,训练参数设置如表3所示。通过与图5虚拟驾驶环境在线交互来训练各DDPG子模块,每当自车行驶一圈或与环境车辆发生碰撞时终止当前训练轮次,重新随机初始化虚拟驾驶环境后开始新的训练轮次,直到完成设定轮次训练。
| 图表编号 | XD00206704000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.25 |
| 作者 | 宋晓琳、盛鑫、曹昊天、李明俊、易滨林、黄智 |
| 绘制单位 | 湖南大学汽车车身先进设计与制造国家重点实验室、湖南大学汽车车身先进设计与制造国家重点实验室、湖南大学汽车车身先进设计与制造国家重点实验室、湖南大学汽车车身先进设计与制造国家重点实验室、湖南大学汽车车身先进设计与制造国家重点实验室、湖南大学汽车车身先进设计与制造国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}