《表6 话头内容识别10折交叉验证结果统计》
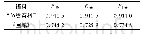 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
图8和表5为话头内容识别10折交叉验证的结果。整体的结果是相对稳定的,两份语料上的10折交叉验证的结果并无太大波动。可以看到,在“鱼类百科”语料中平均F1dis的数值为0.911,而《围城》语料上,平均F1dis仅有0.734 8,两者的结果相差甚大,将近18%,而两个语料上话头检测的结果相差是7.07%。为了准确分析话头内容识别的效果,本文设计了一组追加实验。在追加实验中,只使用标点句ca+1话头缺失的样本,在两份语料上分别训练模型,同样使用10折交叉验证,实验结果如表6所示。可以看到,相较于使用完整的数据,仅使用话头缺失语料的平均F1dis结果均有一定的提升,“鱼类百科”提升了0.003 3,而《围城》提升了0.045 4。这说明数据中不缺失话头的标点句的比例会影响模型的预测结果,相对而言,“鱼类百科”语料中话头自足的标点句所占比例很小,影响也较小,因此本文提出的话头检测和话头识别两个指标相比,ACC单一指标更能精确地衡量模型的性能。
| 图表编号 | XD00202103600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.05 |
| 作者 | 张禹尧、蒋玉茹、毛腾、张仰森 |
| 绘制单位 | 北京信息科技大学智能信息处理研究所、北京信息科技大学智能信息处理研究所、北京信息科技大学智能信息处理研究所、北京信息科技大学智能信息处理研究所 |
| 更多格式 | 高清、无水印(增值服务) |

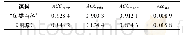
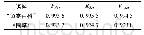
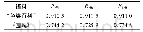


{kind=link}