《表3 不同优化参数下的10折交叉验证F1比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
如表3所示,参数优化对本文实验研究起了重要的作用。针对不平衡的微博数据,对于参数优化问题可分层进行。在每层利用网格搜索,逐步为模型找到最佳参数。在该实验中,为降低计算难度,本文将优化分为2步:1)使用默认参数C,利用网格搜索得到最佳γ值;2)用第1步中的最佳γ值,利用网格搜索得到最佳C值。每个步骤的验证结果见表3,其中最后一列显示了对SVM模型最终优化后的评估结果。与使用默认参数的情况相比,“精神疾病”和“自杀”类别下的F1值显著提高了12.93%和3.13%,而其他类别提高较少。对于该实验结果,可以从以下几方面进行解释:1)收集的数据数量仍然有限;2)本文所使用的情感词典可能更注重自杀风险,而不是愤怒状态;3)不平衡数据使得权重分配不够精确。
| 图表编号 | XD002458800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.05 |
| 作者 | 庄婷婷、李冬梅、檀稳、王广新 |
| 绘制单位 | 北京林业大学信息学院、北京林业大学信息学院、北京林业大学信息学院、北京林业大学心理系 |
| 更多格式 | 高清、无水印(增值服务) |
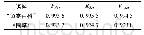
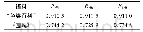
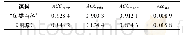

{kind=link}