《表1 机器学习分类10折交叉验证预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于机器学习,首先,需要将分子转换成一系列特征描述符,文中使用RDKit计算MACCS、ECFP4、torsion、RDK5等分子指纹来表征分子。将IC50转换成pIC50,且pIC50≥6.3的化合物视为机器学习法中有活性的化合物,pIC50<6.3的化合物视为机器学习法中不具有活性的化合物[10]。研究采用了最新的机器学习方法包括RF、SVM和MLP,可以把这种预测归结为一个二元分类问题。同时,运用10折交叉验证以评估模型的泛化能力。即重复随机产生子样本的方法将样本平均分成10份,其中,9份作为训练集构建模型,一份作为测试集验证模型准确度,平均10次的结果。在药物发现领域存在着许多评估不同分类方法的准确性和等级的性能度量,文中选择了sensitivity、specificity、accuracy、ROC-curve作为评估模型质量的度量,因为它们分别具有最小化假阴性(FN)和假阳性(FP)错误的能力[11]。对于训练出的几个模型选择最优模型,是利用这些模型筛选天然化合物数据库(2.5×105个小分子),以预测新的潜在BRD4抑制剂。机器学习法分类模型根据python脚本建立,联合10折交叉验证方法高了训练集的预测精度,详细结果参见表1和图3。在BRD4的数据集上,用ECFP4表征分子时,这3个模型都表现得很好,平均AUC达到90%。随机森林模型(random forest)和支持向量机(SVM)模型性能最好。人工神经网络性能稍差的一个原因可能是数据太少,无法训练出较好的模型。
| 图表编号 | XD00149143000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 罗小娇、杜星锴、何俊、冯蓉 |
| 绘制单位 | 四川大学华西医院生物治疗国家重点实验室、四川大学华西医院生物治疗国家重点实验室、四川大学华西医院生物治疗国家重点实验室、云南省妇幼保健院 |
| 更多格式 | 高清、无水印(增值服务) |

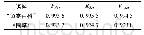
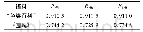
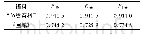


{kind=link}