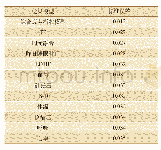
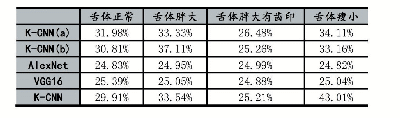
《表2 疲劳检测各模型10折交叉验证结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
继续采用SPSS第23版,运用K折交叉验证的方式,将样本随机分割为K个等样本量的子样本,重复K次拟合计算:每次使用其中任意K-1个样本拟合模型,再用剩余的1个样本计算拟合误差。将K个误差平均即为某个模型的估计误差。最终通过比较不同模型的估计误差(预测标准误差),越小证明模型拟合程度越高。本研究采用10折交叉验证,模型采用分类回归决策树,对比前面建立的综合疲劳指数模型与单一指标模型检测疲劳的拟合度。SPSS软件在“分析”下拉菜单“分类”之“决策树”中设置相应变量,将生长法选为分类回归树(CRT,Classification Regression Tree),即可输出采用决策树的K折交叉验证的拟合度,结果显示,综合疲劳指数模型拟合度最好,优于单个指标反映疲劳状态的效果。具体结果汇总,如表2所示。
| 图表编号 | XD0077084100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.25 |
| 作者 | 黄志强、张芳芳、顾卓筠、陈涛、顾苏、王灵眼 |
| 绘制单位 | 复旦大学附属华山医院博士后流动站、上海惠诚科教器械股份有限公司研发中心、华东师范大学心理与认知科学学院、上海惠诚科教器械股份有限公司研发中心、中国铁路济南局集团有限公司济南机务段、中国铁路济南局集团有限公司济南机务段、中国铁路济南局集团有限公司济南机务段 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}