《表9 多模态融合的结果:真实环境下的多模态情感数据集MED》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
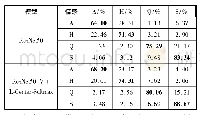
从3.2和3.3节给出的3种单模态的基线看出,单模态的情感识别均能达到不错的效果。相对于单模态,多模态能起到相互补充的作用。MED的数据中包含姿态、人脸和语音,这3部分都对情感的判断起到了一定的作用,当看不到或看不清人脸时,姿态和声音能够帮助进行识别。因此需要对3种情感表达进行综合分析。利用面部表情识别方法(Simonyan和Zisserman,2014a)、姿态情感识别方法(Hara等,2018)和情感语音模型(Eyben等,2013)进行多种方式的融合。首先使用Ben-Younes等人(2019)提出的融合模型对3种模态进行特征集融合,仅有0.04的提升。之后又尝试了Ben-Younes等人(2019)提出的其他几类融合方式,效果均不佳。最后利用决策级融合的方法(Yan等,2018)得到了表9中的结果。在预测阶段,每个模型都会预测样本属于相关情绪的概率。给每个模型分配适当的权重,得到的概率为
| 图表编号 | XD00201376600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.16 |
| 作者 | 陈静、王科俊、赵聪、殷超群、黄自强 |
| 绘制单位 | 哈尔滨工程大学自动化学院、哈尔滨工程大学自动化学院、哈尔滨工程大学自动化学院、哈尔滨工程大学自动化学院、哈尔滨工程大学自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}