《表1 数据应用与来源:基于重要性池化的层级图表示学习方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从基准数据集[10]选择4个常用的图分类数据集。1)D&D:该数据集包含1 178个蛋白质结构,每个蛋白质由一张图表示,其中节点代表氨基酸,若2个节点之间的距离小于6,则建立一条边,预测任务是将蛋白质结构分类为酶、非酶。2)PROTEINS:一组蛋白质分子交互网络数据集,节点代表二级结构元素,若节点处于氨基酸序列或紧密的3D空间,则建立边缘,预测任务是对蛋白质功能进行判断。3)NCI1:非小细胞肺癌活性筛选的化合集的平衡子集,预测任务是将每种酶分为2类。4)MUTAG:由188种化合物组成的数据集,节点表示原子,边缘表示化学键,预测任务是根据化合物对细菌的诱变作用分为2类。数据集主要参数如表1所示。每个数据集10%作为训练集,其余为测试集。
| 图表编号 | XD00190343400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 张红梅、李浩然、张向利 |
| 绘制单位 | 桂林电子科技大学信息与通信学院、桂林电子科技大学广西高校云计算与复杂系统重点实验室、桂林电子科技大学信息与通信学院、桂林电子科技大学信息与通信学院、桂林电子科技大学广西高校云计算与复杂系统重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
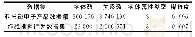





{kind=link}