《表2 两种聚类方法在基准数据集中性能比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
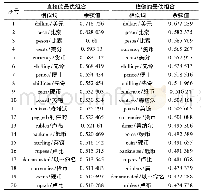
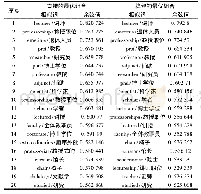
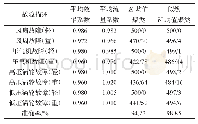
表2给出了K均值方法及似然K均值方法在基准数据集中性能比较,从表中可以看出,在每一个数据集中,似然K均值算法的错误聚类数均比K均值的聚类数要少,因此聚类准确率更高。对于一些样本特征离散程度差距较大的数据集,似然均值聚类算法对聚类准确率的提升效果尤其明显。例如Iris数据集,图6给出了在该数据集中两种聚类方法的效果比较,由图中可以看出,似然K均值算法可以有效地减少误分类点的个数。
| 图表编号 | XD00163006200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 卢俊杰、黄金泉、鲁峰 |
| 绘制单位 | 南京航空航天大学能源与动力学院江苏省航空动力系统重点实验室、南京航空航天大学能源与动力学院江苏省航空动力系统重点实验室、南京航空航天大学能源与动力学院江苏省航空动力系统重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}