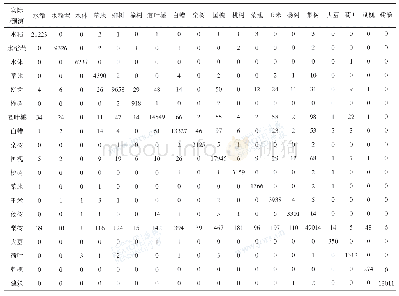
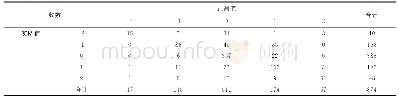
《表2 混淆矩阵:一种聚类欠采样策略的随机森林优化方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
针对不平衡数据的分类任务来讲,不能单纯地从分类精度去衡量一个模型的好坏。如一个100条数据的样本集,其中正类样本为90,负类样本仅为10,不平衡率达到9.0,如果某分类模型将这100个样本全部划分成为正类,则此时的分类精度高达90%,显然这种评价方式极不合理。因此本文选用分类任务中的其他评价指标对算法的有效性进行验证,分别为精确率(Precision)、召回率(Recall)、F值和AUC值,为了更直观地给出这些评价指标的计算公式,需要用到的混淆矩阵如表2所示。
| 图表编号 | XD00188992500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.15 |
| 作者 | 罗计根、杜建强、聂斌、李欢、聂建华、陈裕凤 |
| 绘制单位 | 江西中医药大学计算机学院、江西中医药大学计算机学院、江西中医药大学计算机学院、江西中医药大学计算机学院、江西中医药大学中医学院、江西中医药大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}