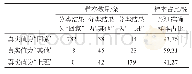
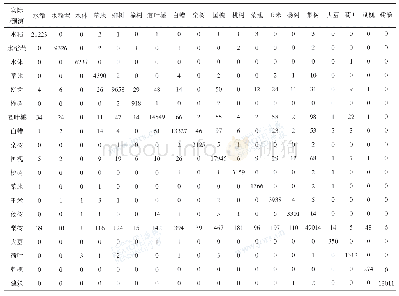
《表1 sample1随机森林分类的混淆矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
像元
构建随机森林模型时需要人为地设置两个重要参数的取值:(1)森林中的树数ntree(number of trees),该值与随机森林模型的收敛性及运行时间成正比,由于随机森林算法计算速度快且不会出现过拟合问题,因此ntree的值应该尽可能的大,但是由于计算机的内存限制,ntree的值通常设置为几百,本文ntree的值设定为100。(2)决策树中每个节点处使用的特征变量个数为mtry,该值大小与随机森林模型中每棵决策树的强度以及决策树之间的相关系数成正比。经过大量的试验证明,当mtry值设定为总特征数的平方根时分类效果最好,本文共使用39个特征,mtry值应设为6。按以上设置的参数对3组样本数据sample1、sample2、sample3分别进行随机森林地物分类试验,试验结果如图3所示。为了定量地分析随机森林分类精度,以sample1的分类结果为例,分类混淆矩阵见表1。由表1可知,树木类几乎完全被正确分类,分类的精度非常高。而容易与建筑物产生分类混淆的地物类别主要是草地、裸地和道路,容易与草地产生分类混淆的地物类别主要是建筑物和道路,容易与道路产生分类混淆的地物类别主要是水体和建筑物,容易与水体产生分类混淆的地物类别主要是草地和裸地,容易与裸地产生分类混淆的地物类别主要是建筑物和道路。
| 图表编号 | XD00200900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 曹爽、潘锁艳、管海燕 |
| 绘制单位 | 南京信息工程大学遥感与测绘工程学院、南京信息工程大学地理科学学院、南京信息工程大学遥感与测绘工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}