《表3 随机森林分类总体精度和Kappa系数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
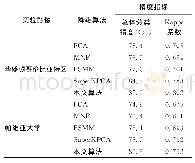
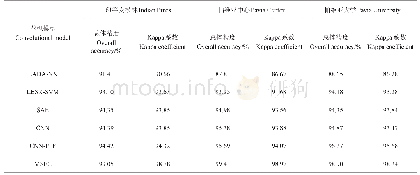
为了选择分类性能最佳和不相关的特征以获得较高的分类精度,采用后向特征选择方法[14]通过迭代逐个消除不必要的或部分相关的特征。首先根据OOB误差计算特征重要性并按数值大小从高到低进行特征变量排序,对最不重要的特征变量进行迭代消除。每次迭代,消除后20%的特征变量。然后利用消除后的新特征变量重新进行随机森林分类,根据OOB误差计算新特征变量对分类结果的重要性并进行排序。该迭代过程一直执行到获得最高分类精度的特征集为止。本文一共进行5次迭代,第1次和第5次迭代的随机森林分类结果如图4所示。表3为利用后向特征选择的随机森林分类结果的总体精度和Kappa系数,由表3可知,随着特征数量的减少,随机森林分类结果的总体精度和Kappa系数均有所提升,直到分类特征数量为16时,分类精度达到最高。但是当特征数量减少到13时,总体精度和Kappa系数开始减小,说明过多地去除特征会使精度下降。经过5次迭代,分类特征数量逐渐从39减少到13,同样根据OOB误差计算13个特征变量对最终分类结果的贡献度可知,对分类地物目标贡献度比较大的几个特征分别为:均值、高程和自相关特征,这与利用后向特征选择之前的特征贡献度排序结果类似。试验表明,本文采用的后向特征选择法比较可靠,即利用后向迭代消除的特征确实是不重要或部分相关冗余特征。
| 图表编号 | XD00201000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 曹爽、潘锁艳、管海燕 |
| 绘制单位 | 南京信息工程大学遥感与测绘工程学院、南京信息工程大学地理科学学院、南京信息工程大学遥感与测绘工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}