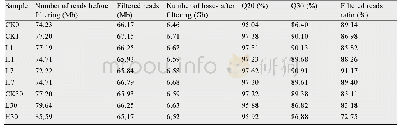
《表2 过滤前后碱基信息及比对分析统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《黄芪多糖对C3H10T1/2细胞棕色脂肪分化中长链非编码RNA表达谱的影响》
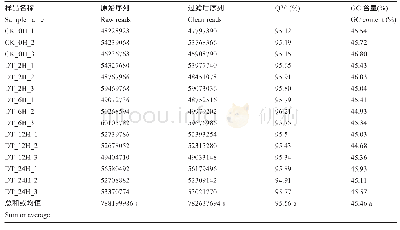
注:Clean data(bp)为下机后经过初步过滤的reads碱基总数;HQ clean data(bp)为clean data经过进一步过滤后得到的reads碱基总数;Q30(%)为测序准确率为99.9%的碱基数目及百分比;N(%)为N碱基的数目及百分比;GC(%)为GC碱基数目及百分比
从Illumina Hi SeqTM4000平台的每个文本库中平均产生了15 177 607 700个清洁数据,在去除不符合的碱基比例和低质量的reads后,从每个库中平均获得了14 831 667 631个高质量的reads。其中,测序准确率为99.9%的碱基数目占比可以达到95.19%~96.34%(表2)。在去除比对上的核糖体reads后,将其比对到小鼠的参考基因组上,有87.76%~90.65%的reads被成功定位到小鼠的参考基因组上(表2)。使用Cufflinks根据比对结果来重构转录本,共得到了13 450个lncRNAs和57 776个m RNAs。使用CPC、CNCI及蛋白数据库Swiss Prot等工具评估新转录本的蛋白质编码潜力,并取结果相交项作为最终结果,我们预测出了586个新lncRNAs转录本(图1a)。
| 图表编号 | XD00149583500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.27 |
| 作者 | 张世和、曹宇鑫、邓步皓、高旭阳、赵俊星 |
| 绘制单位 | 山西农业大学动物科技学院、山西农业大学动物科技学院、山西农业大学动物科技学院、山西农业大学动物科技学院、山西农业大学动物科技学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}