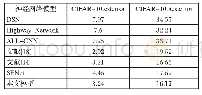
《表1 实验数据设置:融合多头自注意力机制的语音增强方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
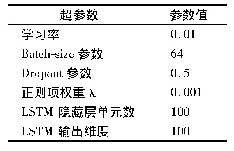
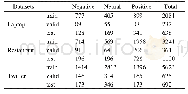
实验数据条件如表1所示。具体合成方法如下:首先将所使用的语音数据均重采样为16 000Hz。其次从中文数据集中随机选取7 000条语音数据(包含700位不同的说话人,每人10条语音)。从-10dB,-5dB,0dB,5dB,10dB信噪比中随机选取一种信噪比,按照该信噪比将干净语音与从训练集噪声中随机选取的两种噪声进行混合,构成14 000(7 000×2)条训练数据。为合成测试集数据,实验从中文数据集中选取与训练集语音数据完全不同的150条语音(包含30位不同的说话人,每人5条语音)。测试集噪声选取了noisex-92数据集中的5种不同噪声,分别是babble、leopard、m109、machinegun和volvo。按照-6dB、0dB和6dB这3种不同信噪比,将150条干净语音和5种噪声进行匹配混合,得到2 250(150×5×3)条含噪语音。
| 图表编号 | XD00140391100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.20 |
| 作者 | 常新旭、张杨、杨林、寇金桥、王昕、徐冬冬 |
| 绘制单位 | 北京计算机技术及应用研究所、北京计算机技术及应用研究所、北京计算机技术及应用研究所、北京计算机技术及应用研究所、北京计算机技术及应用研究所、北京计算机技术及应用研究所 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}