《表2 实验参数设置:基于卷积注意力机制的情感分类方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
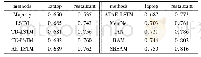
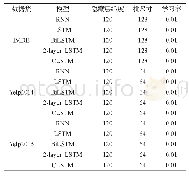
该模型可以通过反向传播以端对端的方式进行训练,损失函数选用交叉熵损失函数,使用Adadelta优化方法提高训练速度。在实验中,word embedding使用Google公开的word2vec 300维向量进行初始化,这是谷歌在新闻数据集上使用1000亿个字训练而成的,囊括了各个领域的词语,也是目前常用的预训练词向量。在对词向量矩阵进行卷积操作时,由于矩阵的每一行代表一个词,所以每一行需要作为一个整体,单独拆开没有意义。因此,实验中卷积核高度为3,宽度等于word embedding的维度。模型其它参数见表2。
| 图表编号 | XD00122848300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.16 |
| 作者 | 顾军华、彭伟桃、李娜娜、董永峰 |
| 绘制单位 | 河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室、河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室、河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室、河北工业大学人工智能与数据科学学院、河北工业大学河北省大数据计算重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}