《表2 混淆矩阵:基于节点地位和相似性的社交网络边符号预测》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由数据集统计信息可知,三个网络数据集中正向边与负向边分布极不均匀,这将导致符号预测的准确率具有较低的可信度。为此,实验过程中采取随机抽样的方法将数据集分成训练集与测试集两部分,依次随机选择10%、30%、50%、…、90%的数据集用于训练,剩余90%、70%、50%、…、10%的数据集用于测试。另外,为了保证预测结果的可靠性,将上述实验重复五次取平均值。使用精确度(accuracy)来评价预测算法对边符号的预测准确率,如式(26)所示。同时,利用混淆矩阵来表示预测结果,如表2所示。
| 图表编号 | XD00134611200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 卢志刚、叶美丽 |
| 绘制单位 | 上海海事大学经济管理学院、上海海事大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |

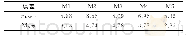



{kind=link}