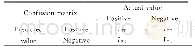
《表2 数字混淆矩阵:基于卷积神经网络的藏文手写数字和字母识别研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
藏文手写数字和字母识别属于分类任务,在分类型模型评判的指标中,常见的方法有如下三种,分别是混淆矩阵(也称误差矩阵,Confusion Matrix)、ROC曲线、AUC面积.本文中使用混淆矩阵对模型测试结果进行评价.以数字混淆矩阵为例,在总的3000个样本中,识别对了2964个样本,所以准确率为2964/3000*100%=98.8%.以数字为例,模型结果告诉我们,3000个数字样本中有300个,但是只有191个预测正确,模型认为是的数字里有一个,两个,六个,即错误的将4识别成了6或8或9.其他数字的分析方式亦是如此,详细见表2.由于字母混淆矩阵数据相对庞大,因此没有在本文中列出.
| 图表编号 | XD00121915900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 周毛克、才让先木、龙从军、闫晓东 |
| 绘制单位 | 中国社会科学院大学(研究生院)、中央民族大学、中国社会科学院大学(研究生院)、中国社会科学院民族学与人类学研究所、中央民族大学 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}