《表9 基于近邻匹配的检验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
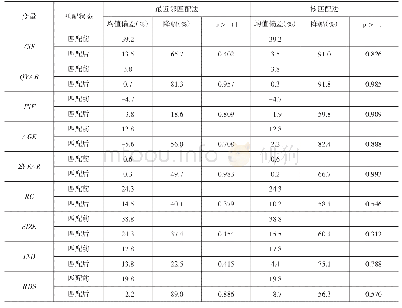
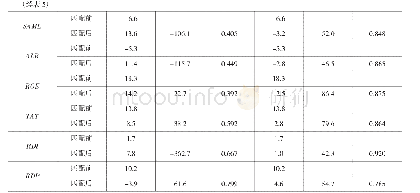
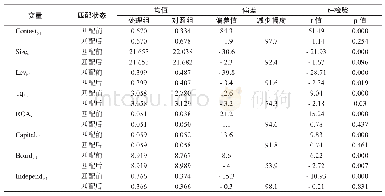
为了确保结果的可靠性,本文又采用倾向得分匹配方法进行检验,以贸易开放的中值为标准,将贸易开放指标大于中值的样本视为处理组,小于中值的样本视为控制组,借助倾向得分匹配方法,能够在控制组中找到最接近于处理组“反事实”状态下的样本,其中“反事实”指的是处理组样本在未贸易开放下的劳动收入份额。然后利用贸易开放国家与假设其未贸易开放情况下的劳动收入份额之差,也即参与者平均处理效应(ATT)值来衡量。若ATT值显著为正,则表示贸易开放对劳动收入份额具有正向作用,反之则具有负向影响。参考吴晓怡和邵军(2019)的做法,采用倾向得分匹配中的近邻匹配法,分别允许控制组中的1个、2个、3个倾向得分最接近的个体来匹配处理组,检验结果如表9所示。从表9中可以看出,全部样本、资本密集型国家、资源密集型国家、制度环境良好国家的估计结果显著为负,高经济发展水平国家、制度环境不佳国家的估计系数为负但不显著,低经济发展水平国家和劳动密集型国家的估计结果显著为正,上述结果与固定效应模型的估计结果基本一致,表明相关结论具有较好的稳健性。
| 图表编号 | XD00130556000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 吴晓怡、邵军、阚哲涵 |
| 绘制单位 | 南京师范大学商学院、东南大学经济管理学院、华东政法大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}