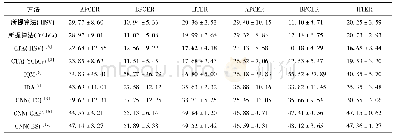
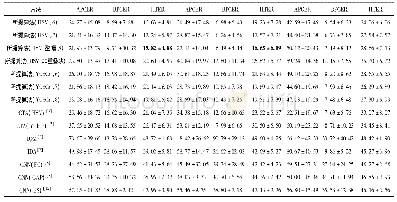
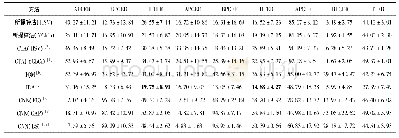
《表1 文本分类实验错误率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
模型在数据集上取得的错误率如表1所示.对于每个任务,选择了目前效果最好的模型进行比较.在IMDb和TREC-6数据集上,与CoVe(context vectors)模型[33]进行对比.在AG、Yelp和DBpedia数据集上,与文献[34-35]提出的文本分类方法进行对比.最后在全部数据集上与目前文本分类效果最好的基于微调的半监督模型ULMFi T(universal language model fine-tuning)[2]进行对比.
| 图表编号 | XD00129609300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 傅群超、王枞 |
| 绘制单位 | 北京邮电大学软件学院、北京邮电大学可信分布式计算与服务教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
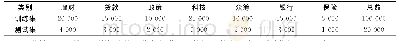


{kind=link}