《表1 CNN文本分类实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
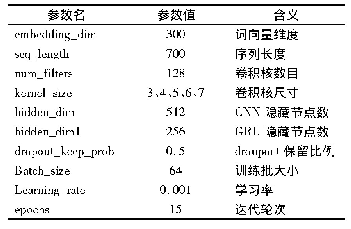
在Kim[3]提出的CNN文本分类模型当中,采用了7个不同的数据集在不同的基准上,分别进行训练及测试,比较其结果.这7个数据集都是评论类的数据集,具体信息参见文献[3].这些数据都是短文本类的数据集.在实验中作者给出CNN的四种变体,分别是CNN-rand(随机初始化单词向量),CNN-static(单通道不可变的预训练单词向量),CNN-nonstatic(单通道可变的预训练单词向量)和CNN-multichannel(双通道可变与不可变相组合的预训练单词向量).将这7个数据集分别在这四种CNN模型中进行训练及测试,进行对比实验,以准确率作为衡量标准,实验结果如表1所示.
| 图表编号 | XD0094894000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 孙嘉琪、王晓晔、周晓雯 |
| 绘制单位 | 天津理工大学计算机科学与工程学院天津市智能计算及软件新技术重点实验室、天津理工大学计算机科学与工程学院天津市智能计算及软件新技术重点实验室、天津理工大学计算机科学与工程学院天津市智能计算及软件新技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}