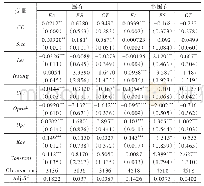
《表8 客户特征分组回归:客户集中度与分析师盈余预测准确性》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
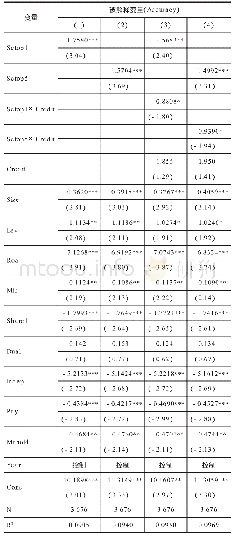
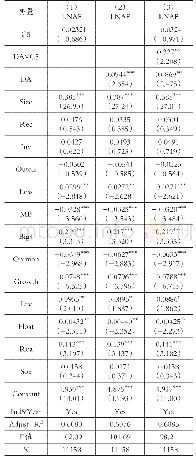
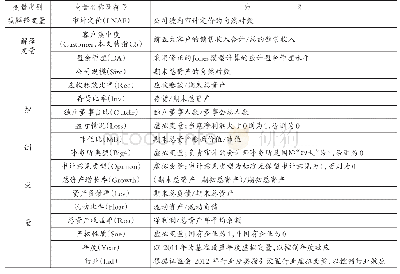
采用分析师个人层面的盈余预测偏差(pmafe)作为公司层面分析师盈余预测偏差的衡量指标。。其中,Afeijt是分析师i对公司j在第t年预测误差的绝对值,是公司j在第t年所有分析师预测误差的平均值。该值越大,表示分析师预测偏差越大。回归模型在控制公司特征的基础上进一步引入了分析师特征层面的控制变量:分析师所在券商规模(bsize),即分析师所在券商的分析师人数的自然对数;分析师预测期间(period),即分析师预测报告的公布日与年报公布日之间的时间间隔;分析师的工作经验(exp);分析师跟踪公司数(cover)。表9报告了分析师层面的预测偏差的回归结果:列(1)以前五大客户销售占比的赫芬达尔指数(hhi)为解释变量,客户集中度(cc)的估计系数为0.0005,在1%的水平上显著;列(2)以前五大客户销售占比(top5)为解释变量,cc的估计系数为0.0003,在5%的水平上显著。从分析师个人层面来看,分析师在进行盈余预测的过程中会关注企业的主要客户信息以及企业客户集中度潜在的信息含量。在变更分析师盈余预测偏差的衡量指标之后,客户集中度仍然显著正向影响分析师盈余预测偏差,对分析师个人而言,企业的客户集中度引发了潜在的风险效应,可见假设1具有一定的稳健性。
| 图表编号 | XD00102103500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.23 |
| 作者 | 包晓岚、赵瑞 |
| 绘制单位 | 华中农业大学经济管理学院、华中农业大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}