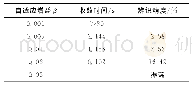
《表2 不同批大小下精度、误差和时间统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在训练深度学习时,我们的主要方法是随机梯度下降法,而批大小的选择决定下降方向,所以批处理大小也是深度学习模型中一个重要的参数。不同的训练样本也会导致批处理大小不同,过大的批处理会导致计算机的内存容量不够,要想达到相同的精度,其所花费的时间大大增加,从而对参数的修正也就显得更加缓慢。所以选择合适的数据集批处理大小,可使缺陷识别模型在最短时间内获得最高的训练精度和泛化能力。为了确定缺陷识别模型的最优批大小,本文将划分多个阶段的批大小来训练网络,获得零件缺陷分类模型的训练精度、训练误差、测试误差和训练时间统计结果,如表2所示。
| 图表编号 | XD006594500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.10 |
| 作者 | 周明浩、朱家明 |
| 绘制单位 | 上海理工大学机械工程学院、上海理工大学机械工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}