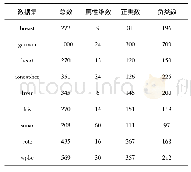
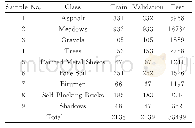
《表1 数据集信息 (数据集,样本总数,属性维数,正类数量,负类数量)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从UCI数据库中选择9个数据集,其属性如表1.利用免疫克隆选择算法做实验时,其种群规模为20,编码长度为其相对应的特征维数,克隆规模取为6,变异概率为0.8,终止条件取最大进化代数为20代.通过选取经典的算法做出对比,其中对比算法KPCA,LE,LLE,LTSA,MDS,PCA[6-11],表2列出的是每次交验验证的分类正确率,每组数据共执行10次得出平均分类正确率.由图12、13可以看出在LLE,LTSA与本文算法效果上较接近,这是由于本文在选取领域近邻点时特别考虑了这些因素对于这两类算法影响较大,所以在前期处理时特别处理了相应的近邻点[12],导致在搜索上模仿全局搜索[13]能力可以较好的实现有区别分类.PCA作为一种全局搜索在部分数据上表现的和本文算法类似如german,ionosphere,表现出了对于数据清除噪声后的效果可能比没有进行清除噪声的全局搜索效果要好或者类似,相反,单纯使用局部搜索(如LE)表现则一般,由此可以看出对于数据进行清除部分噪声的作用还是明显的.
| 图表编号 | XD0065117700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 韩保金、曾岳 |
| 绘制单位 | 天津工业大学计算机科学与软件学院、金陵科技学院软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}