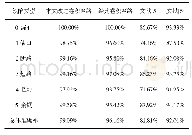
《表8 无噪声下多种算法识别f2结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
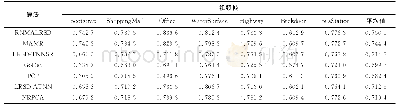
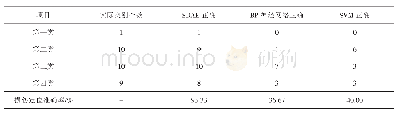
从表6-7可以看出,由于采取平均值作为识别值,故结果与实际偏离较大。实际计算中,两种算法的识别结果均收敛于[6,0.66,0.4,0.22]与[0.998,0.372,0.19,0.64]两组值。显然,第一组接近真实值,为正确搜索结果;第二组与真实值偏差大,显然是算法陷入了局部最优。可以观察到,在噪声高的情况下,平均识别结果甚至还更好,显然是噪声的存在反而使得第二组数据出现概率更低,识别平均值更佳,这说明两种算法全局搜索能力普遍不如BMO。而粒子群由于寻优计算机制单一,相比拥有变异机制的遗传算法更差,其粒子个体的速度在搜索后期基本趋近于零。算法设定的粒子速度范围选择上约束性也很强。因为其粒子在前期维数更新中极其活跃,过快的速度会使识别值趋向于参数取值范围两侧的局部最优点,过慢的速度会使粒子快速趋于静止,这两种现象还会因前几代个体的具体值在局部最优值附近而加重,使得在初期搜索中即收敛,形成“早熟”现象。为进一步比较算法的局部搜索能力,选择GA与PSO中无噪声情况下的一组正确识别数据,并与BMO的一组识别值进行精度上的对比,结果见表8。
| 图表编号 | XD0063712800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 谭栋、汪利、吕中荣 |
| 绘制单位 | 中山大学航空航天学院力学系、中山大学航空航天学院力学系、中山大学航空航天学院力学系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}