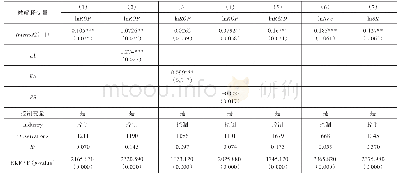
《表4 高铁服务供给强度对制造业集聚影响的工具变量法估计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:表中括号()内为稳健标准误,***,**和*分别表示在1%,5%和10%水平上显著;[]为统计量对应的p值。
在上文中,采用最小二乘法就高铁服务供给强度对制造业行业集聚的影响进行了估计。然而,作为一种重要交通设施,高铁服务供给强度的高低取决于地区出行需求和国家或地区层面高铁规划。制造业集聚程度较高的地区,通常集聚着大量的就业人口,使得集聚区出行的交通需求较大。在需求驱动下交通规划部门通常更倾向于在制造业就业人口较多的地区建设高铁,因此高铁服务强度与制造业集聚之间可能存在逆向因果关系,由此可能导致内生性问题。解释变量的内生性将导致OLS并不能得出一致估计。因而,为了有效避免内生性问题,本文采用工具变量法进行估计。选取高铁服务供给强度作为内生变量,并采用2006年各省份铁路客运总量和铁路列车日出行频次作为高铁服务强度的工具变量,这主要是因为2006年全国各省份均未出现高铁客运专线,然而,2006年的各省份铁路客运量和铁路列车日出行频次直接反映了当地对铁路客运的需求和原有的铁路基础设施状况,当时的铁路客运需求和铁路基础设施状况与2008年后各省份高铁服务供给存在密切相关关系,因为2008年后高铁客运专线一部分是由原来的普通铁路客运线改造而来,同时在高铁规划中也优先向铁路客运需求较多地区倾斜(2)。另一方面,2006年各省份铁路客运量和铁路列车日出行频次作为历史的前定变量,也满足了外生性条件。当然,要获得有效的工具变量,必须对工具变量的有效性进行检验。表4报告了基于工具变量的回归结果,在表4下半部分,报告了工具变量有效性的几种检验,过度识别检验中Hensen J统计量所对应的P值均不显著,检验结果接受了不存在过度识别的原假设,而不可识别检验显示Kleibergen-Paap rk LM统计量对应的P值均为0.000,强烈拒绝了不可识别的原假设,说明工具变量均为外生变量。Cragg-Donald Wald F统计量显示对于名义显著性水平为5%的检验,其真实显著性水平不会超过15%,因此,有理由认为不存在弱工具变量问题。基于稳健性考虑本文还使用了对弱工具变量更不敏感的有限信息最大似然法(LIML)进行估计,系数与2SLS估计结果相似,这进一步证明了不存在弱工具变量问题。使用工具变量的前提是存在内生解释变量,由于异方差情形下,传统的Hausman检验失效,而异方差检验表明存在异方差问题,为此本文进行了异方差稳健DWH检验,从表4可看出Wu-Hausman F检验结果拒绝了所有解释变量均为外生的原假设,因此可认为高铁服务强度HSR为内生解释变量。一般地,异方差情形下GMM相对于2SLS更有效率,在表4本文同时报告了2SLS和两步最优GMM回归结果,考虑到制造业集聚具有路径依赖和动态递延特征,故在两步最优GMM估计中加入了因变量的滞后项。从各列回归的R2对比看,两步最优GMM估计中的R2值要明显高于2SLS,因此,在后文的实证中,均采用更有效的两步最优GMM方法进行模型估计。从表4各列回归结果来看,控制了内生性后,高铁服务供给强度的系数依然为负值,且均在1%水平上显著,说明高铁服务供给强度的提高确实会对制造业整体集聚产生负向抑制效应,促进了制造业的空间扩散。
| 图表编号 | XD0054575800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.20 |
| 作者 | 朱文涛 |
| 绘制单位 | 集美大学财经学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}